アンケートの自由回答データ入手できたので、業者にテキストマイニングを依頼。
数社の見積もりを取ったところ、簡易レポートつきで30万~50万くらい。
某電々系SIerに発注したところ、PPTのテンプレートだけがcoolなショボい納品物に眩暈がしたので、オープンソースなテキストマイニングツールを探してみた。
KH Coder
KH Coderとは、内容分析(計量テキスト分析)もしくはテキストマイニングのためのフリーソフトウェアです。新聞記事、質問紙調査における自由回答項目、インタビュー記録など、社会調査によって得られる様々な日本語テキスト型データを計量的に分析するために製作されました。
Windows版では、その他の必須ソフトウェア(ChaSen + MySQL + Perl + 各種Perlモジュール)はKH Coderの配布パッケージに同梱されています。また、これらの必須ソフトウェアの設定はKH Coderが自動的に行います。
なんか良さげなので、会社でインストール申請出す前に自宅でテスト。
とりあえずWindows版のバイナリで、このサイトの検索キーワードをマイニングしてみた。
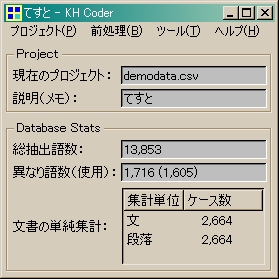
元ネタは、Google Analyticsから。2,664種類のフレーズを.csvで入手。
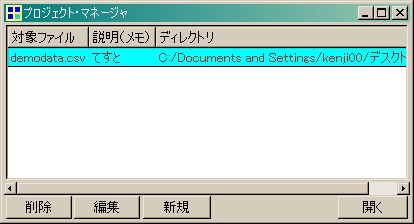
[起動して]
[ファイルを読み込んで]
[前処理を実行]
[処理完了]
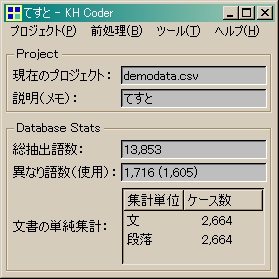
すると
[品詞別の出現回数]
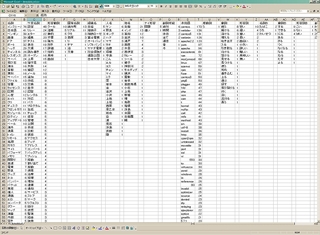
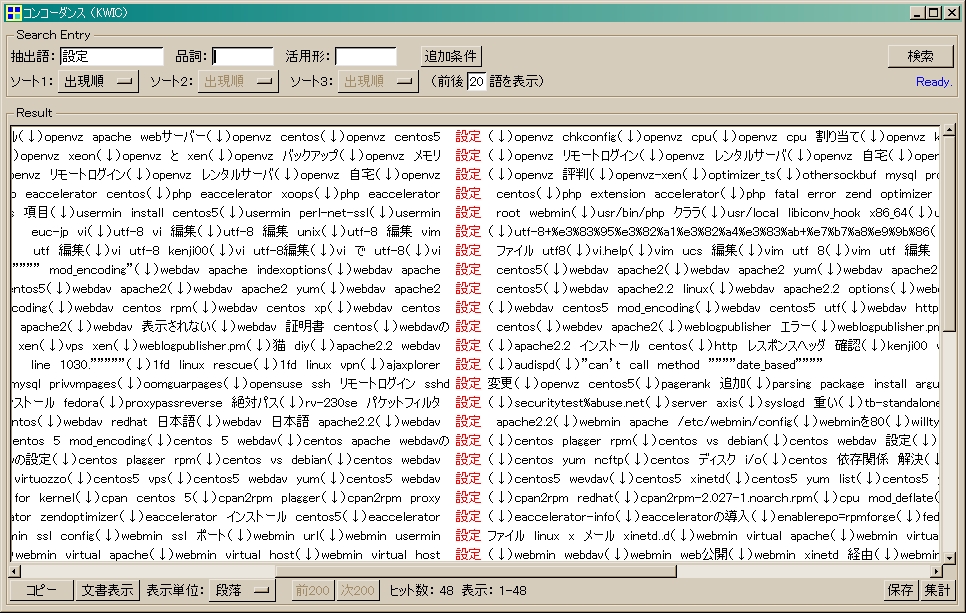
[KWIC(keyword in context)]
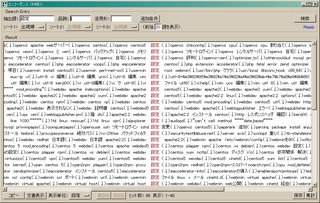
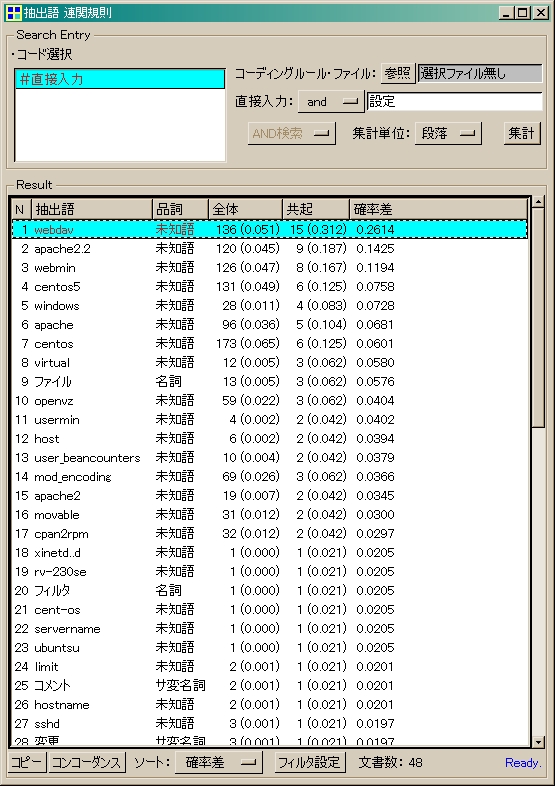
[連関規則]
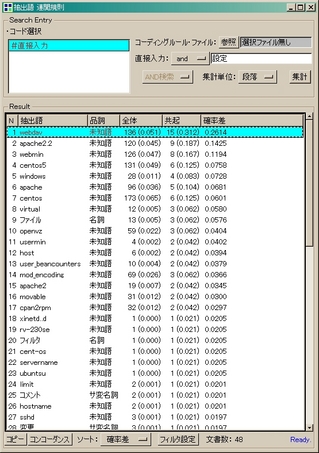
といったデータが簡単に解析できます。
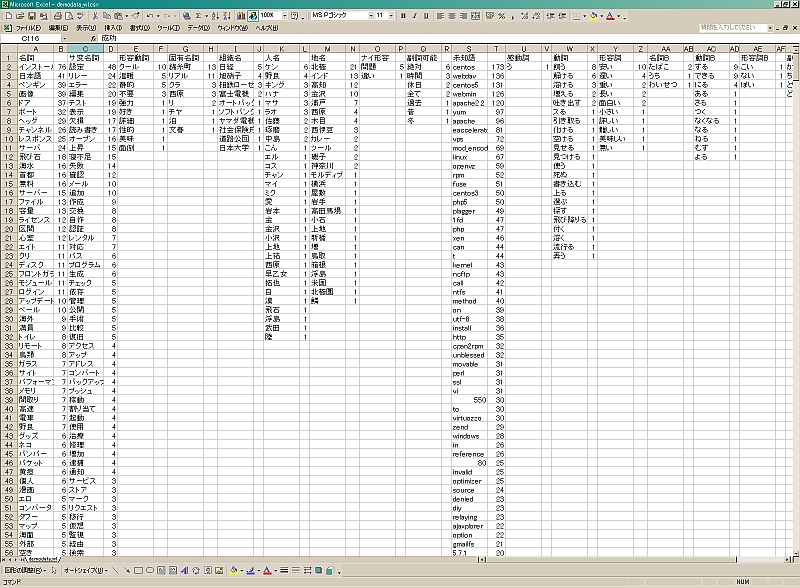
その他にも、外部変数として読み込んだデータとのクロス集計やワードの出現回数分布、コロケーション(共起)統計もできちゃう。さらにExcel上で整形・グラフ化するためのマクロ付き。
外注すると30万の納品物があっという間にお手元に。
今回の様に検索キーワード解析だと、CVRの良いワードと相関の高いSEM入札/SEO用ワードを探したり...といった作業も楽に行えると思われ。
Perlのソースも配布されていることですし、コレでwebサービスしたら便利だと思うなぁ。




最近のコメント